機器學習VS深度學習
截止2026年,深度學習模型已經佔據AI領域的半壁江山,但它與機器學習相比,好在哪裡?
在AI發展早期階段,專家係統頗為流行,模型的預測依賴於專家對規則的指定,比如,if一個物體是圓的,紅的,帶有綠葉子,so它是一個蘋果。我並不認為它是一個真正意義上的模型,它沒有學習能力,它的結果完全依賴與專家的定義。
在AI發展的中期階段,機器學習頗為流行,此時模型特征的選擇依舊要來靠領域專家來判斷,而與專家系統不同的是,它引入了權重的概念,一些特征乘以一些權重,結果就是它是蘋果的概率,既然有了權重,那麼這個模型就有了學習的能力。它變得不再絕對,泛化能力變強。
如今,深度學習頗為流行,這得益於當今算力的提升,在DL中,我們不需要再去告訴模型特征,只需要把輸入和結果告訴模型,模型自然會去提取裡面的特征,發現裡面的規律,這對我這個學計算機的人來說,非常友好。
一句話總結,機器學習就像小孩子學習,父母指出重點,小孩子來學。而深度學習就像是成人自學,因為他已經有了判斷重點的能力。

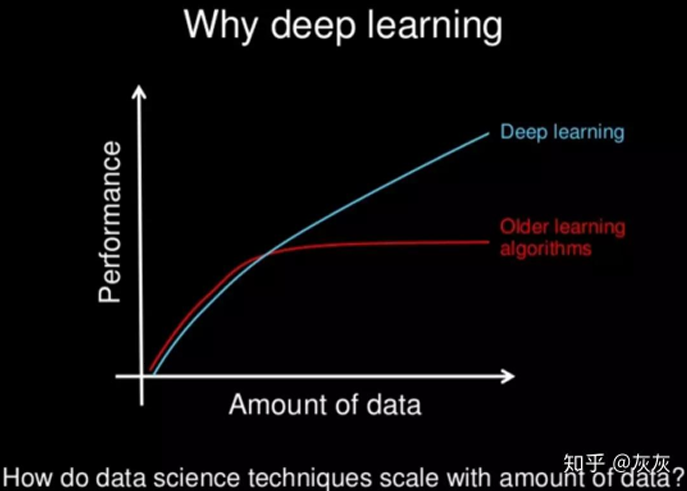
而對比它們的學習效率,深度學習在數據量不夠多時,甚至比不上機器學習,但一但達到了一定閾閾值,機器學習就會出現飽和現象,而深度學習則會繼續上升,也就是說它的上限很高。
單個神經元的數學模型
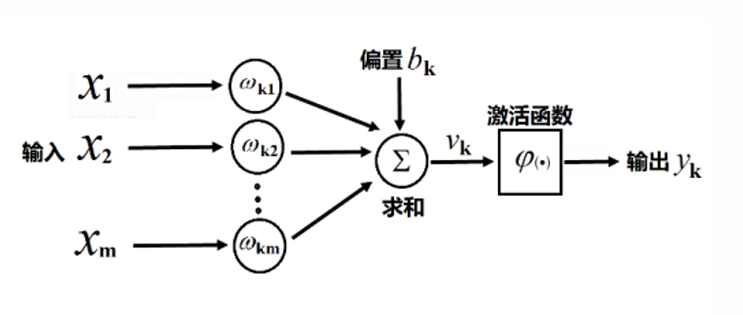
單個神經元這麼計算:y(predict)= w1 * x1 + w2 * x2 + … + b
常見的神經網絡
神經網絡由神經元組成,但有不同的組成結構,其基本單位都是一個一個的神經元。
- 感知機:也就是只有輸入層與輸出層的多層感知機,並沒有隱藏層,這是最簡單的深度學習模型架構。
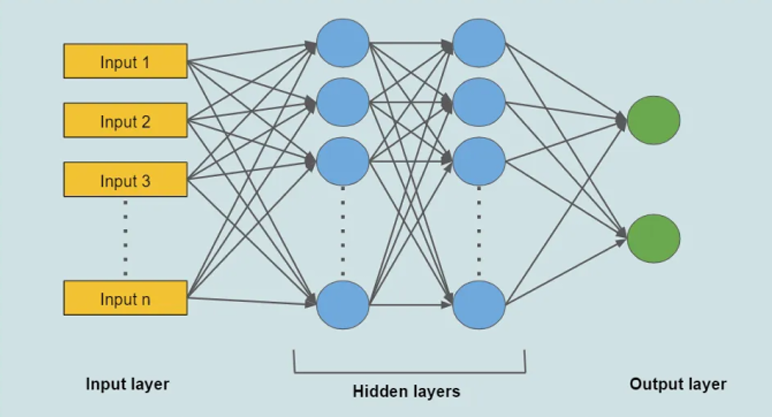
- 多層感知機(全連接神經網絡):感知機的拓展,包含輸入層、隱藏層、隱藏層…輸出層等多層結構,一個層的每個神經元都鏈接相鄰兩層的所有神經元。
-
卷積神經網絡(CNN):廣泛用於計算機視覺。
-
循環神經網絡(RNN):廣泛用於時序信息,可以存儲前期信息(記憶)。比如股票,文本等。
-
生成對抗網絡:主要用於圖片生成與增強,現已被擴散模型逐漸取代。
-
Transformer:還沒學,後期更新。
損失函數
損失函數作用於模型最終輸出預測結果之後。一句話講,損失函數就是判斷模型預測值與真實值差距的一個算法,這個算法的好壞決定著判斷模型準確性的標準。
分類(分割)任務用交叉熵損失函數。
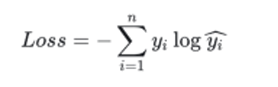
回歸任務用MSE(均方誤差)
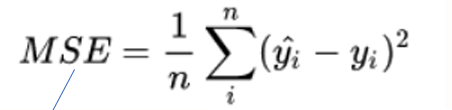
激活函數
而激活函數用於單個神經元的末尾,將原本的線性組合注入激活函數擁有非線性能力,其包含:sigmoid、softmax、ReLu、Leaky-ReLu。
隱藏層:分類和回歸的隱藏層都推薦使用ReLu或Leaky-ReLu。
輸出層:二分類輸出層推薦sigmoid,多分類輸出層推薦softmax進行歸一化。回歸輸出層不用激活函數或用線性激活。
sigmoid每個輸出獨立計算,範圍(0,1)。多個sigmoid輸出的和不一定等於1。
softmax所有輸出之和嚴格等於1,形成完整的機率分佈。